
Linguistically, the word “reliability” occurs in contexts of relying on something, for example, on one’s tools, someone else’s service, given measuring instruments, or data. In the conduct of science, the reliability of data is an important bottleneck for the construction of theories or scientific conjectures, and for giving reasonable advice.
Data usually are the primary and therefore the most direct representations of typically transient phenomena that researchers are interested in theorizing, conceptualizing, or explaining. Interviews, public happenings, historical events, natural catastrophes, even scientific experiments do not last long enough for important details to be inspected. Moreover, phenomena cannot be compared unless they co-occur. Analysis, comparison, and research of diverse transient and non-synchronous phenomena cannot proceed without relying on sufficiently durable representations of them: data for short. Even archaeological artifacts that have endured natural decay, often thought to be direct and unmistakably obvious data, are not data unless they can be seen as the products of a distant culture that archaeologists seek to understand. Observations, when committed to memory, may seem individually more real than phenomena talked about by others, but they have no intersubjective status until they are recorded, described, or transcribed, until they have become data for more than one person. Thus, one speaks of data when a community can handle them in the absence of phenomena of interest to that community.
Epistemology Of Reliability
Reliability is a measure of the extent to which a community can trust data as stand-ins for unavailable phenomena. Sources of unreliability are many. Measuring instruments may malfunction, be influenced by variables that are irrelevant to what is to be measured, or be misread. When asked for their opinions, interviewees may answer to please the interviewer. Witnesses may testify from recollections that are distorted by self-interests, enriched by recent insights, or informed by explanations heard from third parties. Medical doctors may disagree on the diagnosis of a patient. Content analysts may have conflicting assessments of what a text means. Demonstrating the reliability of data means ruling out all conceivable sources of uncertainty that could have contributed to the data’s present form.
Assessing the reliability of data entails two epistemological difficulties. Not only are many phenomena that data aim to represent transitory, but, even when they are not so, it is the act of generating data that makes them into known phenomena. For example, one does not know the time of the day unless there is a clock to observe. One does not know the meaning of a text unless one reads it. One does not know the category of an event unless someone categorizes it. Data are relatively durable descriptions that create what they describe. This fact is the most important reason why researchers need to assure themselves and each other that the data they have generated or obtained from other sources are reliable in the sense of representing something real and are, hence, worthy of attention. Obtaining such assurances presents two problems: how to assess the reliability of data, and once measured, whether their unreliability is tolerable or not.
Two Compatible Concepts Of Reliability
There are two concepts of reliability in use. (1) From the perspective of measurement theory, reliability amounts to an assurance that a method of generating data is free of influence from circumstances that are extraneous to the processes of observation, description, or measurement. Establishing this kind of reliability means measuring the extent to which the variation in data is free of variation from spurious causes. Such tests require duplicating the data-making effort under a variety of circumstances that could affect the data. These duplications must be independent of each other and obtained under the very conditions under which one would like the data to be stable. For example, if human coders are involved, one wants to use coders whose kind can be found elsewhere. For interview data, one wants to be sure that the personality of the interviewer does not affect what interviewees say.
If the temperature of medical patients is measured, one may want to be sure that room temperature does not influence the outcome. The extent of agreement among these duplications is interpreted as the degree to which data can be considered reliable and, hence, trusted.
(2) From the perspective of interpretation theory, reliability amounts to an assurance that researchers interpret their data consensually. Establishing this kind of reliability means demonstrating that the members of a scientific community agree on the meaning of the data they analyze. Unlike measurement theory, interpretation theory recognizes that researchers may have different backgrounds, interests, and theoretical orientations that lead them to different interpretations of the same data. Seeing the same phenomenon from different perspectives is typical, often considered instructive, and not counted as evidence of unreliability. It is when data are taken as evidence about phenomena not under researchers’ control, say, about historical events, witness accounts, or statistical facts, that unreliability can become an issue. A method for establishing this kind of reliability is triangulation. Data are reliable when, after accounting for explainable differences in approaches and perspectives, three or more sets of data imply the same thing. Unreliability becomes evident, however, when one researcher’s claim of what the data represent contradicts the claims made by others. When one researcher considers his or her data as evidence for “A” while others consider their data as evidence for “not A,” the two claims cannot both be true. Data that cannot be triangulated erode an interpretive community’s trust in them. From the perspective of interpretation theory, therefore, reliability assures a community that its members are talking about the same phenomena – without availability of these phenomena independent of talking about them.
Whereas measurement theory focuses on the process of generating data and attempts to assure researchers that their data are representative of real as opposed to spurious phenomena, interpretation theory concerns itself with what measurement theory tries to accomplish, namely that researchers agree regarding whether they are investigating the same phenomena. Both concepts of reliability rely on achieving substantial agreement.
Reliability And Agreement
The reliability of a particular technological device often is an either/or proposition; for example, does the engine of a car start or not? The reliability of a class of devices usually is the failure rate of its members, indicated by a statistic; for example, the repair record of a particular model of car. However, when humans are involved in generating data, especially by recording observations or reading texts – from recording the numerical values read from a measuring instrument to judging whether published statements are favorable or unfavorable to a candidate for political office – their reliability depends on agreement among independently obtained records of observations, readings, or judgments.
Agreement is not truth, and reliability, therefore, must not be confused with validity. Validity is the quality of research results, statistical findings, measurements, or propositions being true in the sense that they do represent the phenomena they claim to represent. To establish validity requires validating evidence. Predictions, for example, are not valid until they come true. By contrast, from the measurement theory perspective, reliability assures that data are generated with all conceivable precautions against extraneous influence from the data-making process; from the perspective of interpretation theory, reliability insures that all available data triangulate and their interpretations are consistent with each other – in the absence of evidence of what these data actually represent. Since validating evidence is rarely available while data are being analyzed, reliability often is the only criterion available to empirical researchers.
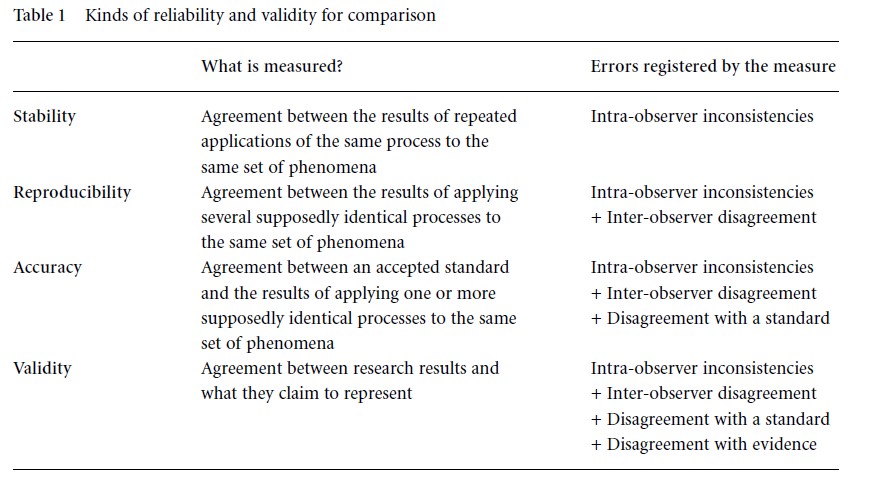
Table 1 Kinds of reliability and validity for comparison
Kinds Of Reliability
There are three kinds of reliability: stability, reproducibility, and accuracy, which may be contrasted with validity. They are distinguished by registering different kinds of errors and having unequal strengths (Table 1).
Stability is also called test–retest reliability, reproducibility test–test reliability, and accuracy test–standard reliability. While all three reliabilities (and incidentally validity as well) are determined by measuring agreement, the data for stability, reproducibility, and accuracy (and validity) differ. As the table suggests, stability reacts to just one kind of error, replicability to two, and accuracy to three. It follows that accuracy is the strongest and stability the weakest form of reliability. In most practical situations, however, replicability is preferred.
Measuring Reliability
From the measurement theory perspective, reliability is the degree to which a data-making process is reproducible in a variety of situations, by different but identically instructed observers or interpreters, or by different measuring devices that are designed to respond to the same phenomena in identical ways. From the interpretation theory perspective, reliability is rarely actually measured, but assessed in terms of the degree to which separate researchers concur in the use of data claimed to be about the same phenomena.
Where humans are involved as observers, researchers, coders, translators, or interpreters, appropriate measures of reliability – reproducibility in particular – must do the following:
- Treat the observers involved as interchangeable (the point of replicability being that any qualified observer should be able to comprehend the given instructions for what is to be done, observe, read, or interpret the phenomena in question, and record them accordingly).
- Measure the extent of the (dis)agreement or (in)compatibilities among many (at least two) independently working observers or researchers regarding the descriptions or categorizations of a given set of phenomena (recording units).
- Compare the observed (dis)agreements or (in)compatibilities with what would be expected when the accounts of these phenomena were chance events. In order to be interpretable as the absence of reliability, chance must be defined as the condition of no correlation between the descriptions collectively used to account for the phenomena in question and the phenomena to which they were meant to apply. For example, chance would be observed when observers assigned their descriptions to the phenomena by throwing dice.
- Be independent of the number and kind of descriptions available to each phenomenon (so as to yield reliability measures that are comparable across variables with different numbers of values or scales of measurement).
- Define a scale that is anchored in at least two points with meaningful reliability interpretations: perfect reliability (typically 1.000) and the absence of any reliability or chance agreement (typically 0.000).
- Yield values that are comparable across levels of measurements, where different levels – nominal, ordinal, interval, and ratio metrics – are involved.
There are only a few statistics that satisfy these criteria, and researchers should examine them in the above terms before settling on one.
Critical Values
The second question concerns the conditions under which somewhat unreliable data may still be trusted for use in subsequent analyses or rejected as too misleading. Some researchers look for a fixed numerical cut-off point in the scale that an agreement coefficient defines. Save for perfect agreement, there are no magical numbers, however. Cut-off points depend on the costs of losing one’s reputation, resources, or affecting others’ well-being by drawing false conclusions from unreliable data. When someone’s life is at stake, for example in criminal proceedings or in medical diagnoses, or when decisions between war and peace are made dependent on imperfect data, the costs of wrong conclusions are high and that cut-off point must be high as well. In academic research, where the consequences of wrong conclusions may be less drastic, reliability standards may be more relaxed but should never be ignored.
While reliable data cannot guarantee valid conclusions – researchers can make mistakes in analyzing perfectly reliable data – unreliable data always reduce the probability of drawing valid conclusions from them. This relationship between reliability and validity renders reliability assessments an important safeguard against potentially invalid research results.
References:
- Krippendorff, K. (2004). Content analysis: An introduction to its methodology. Thousand Oaks, CA: Sage.